引言
自然语言理解(NLU)
Natural language understanding (NLU) is a subtopic of natural language processing in artificial intelligence that deals with machine reading comprehension. NLU is considered an AI-hard problem. [1]
从概念定义可以得出的信息
- 属于 NLP 的一个分支
- 属于人工智能的一个部分
- 用来解决机器理解人类语言的问题
- 属于人工智能的核心难题
补充一句,什么是 AI-complete 或 AI-hard 问题?其实就是说解决这个问题的难度等同于让计算机和人类一样智能,或者说实现它就相当于实现了 strong AI,基本标志 AI 革命的完美结束。
语义表示(Semantic representation)
语义表示(Semantic representation) 有三种典型形式:
- 分布语义表示(distributional semantics representation)
把语义表示成一个向量,如 word2vec、LSA、LDA 及各种神经网络模型(如 LSTM)
基于Harris的分布假设:semantically similar words occur in similar contexts
对人机交互而言,这种表示方法缺少一个细节性/可解释的表示,不能说出第 n 维表示什么
NLP 笔记 - 再谈词向量 - 模型论语义表示(model-theoretic semantics representation)
把自然语言映射成逻辑表达式(logic form)
在计算方法上,典型的就是构建一个semantic parser
难度比较大,见NLP 笔记 - Meaning Representation Languages的一阶谓词演算和 lambda reduction。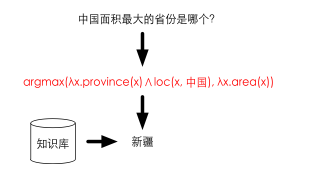
- 框架语义表示(frame semantics representation)
这种表示方法对人机交互非常有帮助
比如说 “订一张上海飞北京的头等舱,下午5点出发,国航的”,把语义用一个frame表示出来,如图所示:
在智能语音交互中,普遍采用frame语义表示,比如飞机票,第一层是 domain,确定是 flight_ticket 这一领域,下一层是这一领域下的 intent,比如说 search_flight_ticket,最下面一层是 intent 下的 slots。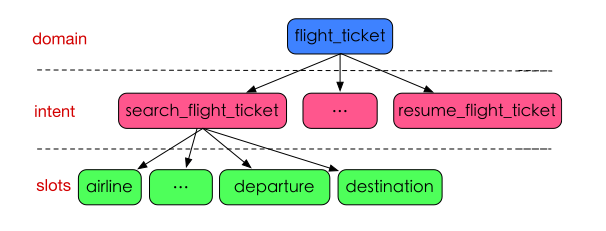
自然语言理解的核心过程,第一步就是对 domain/intent 分类,然后接着对 slot 进行填充。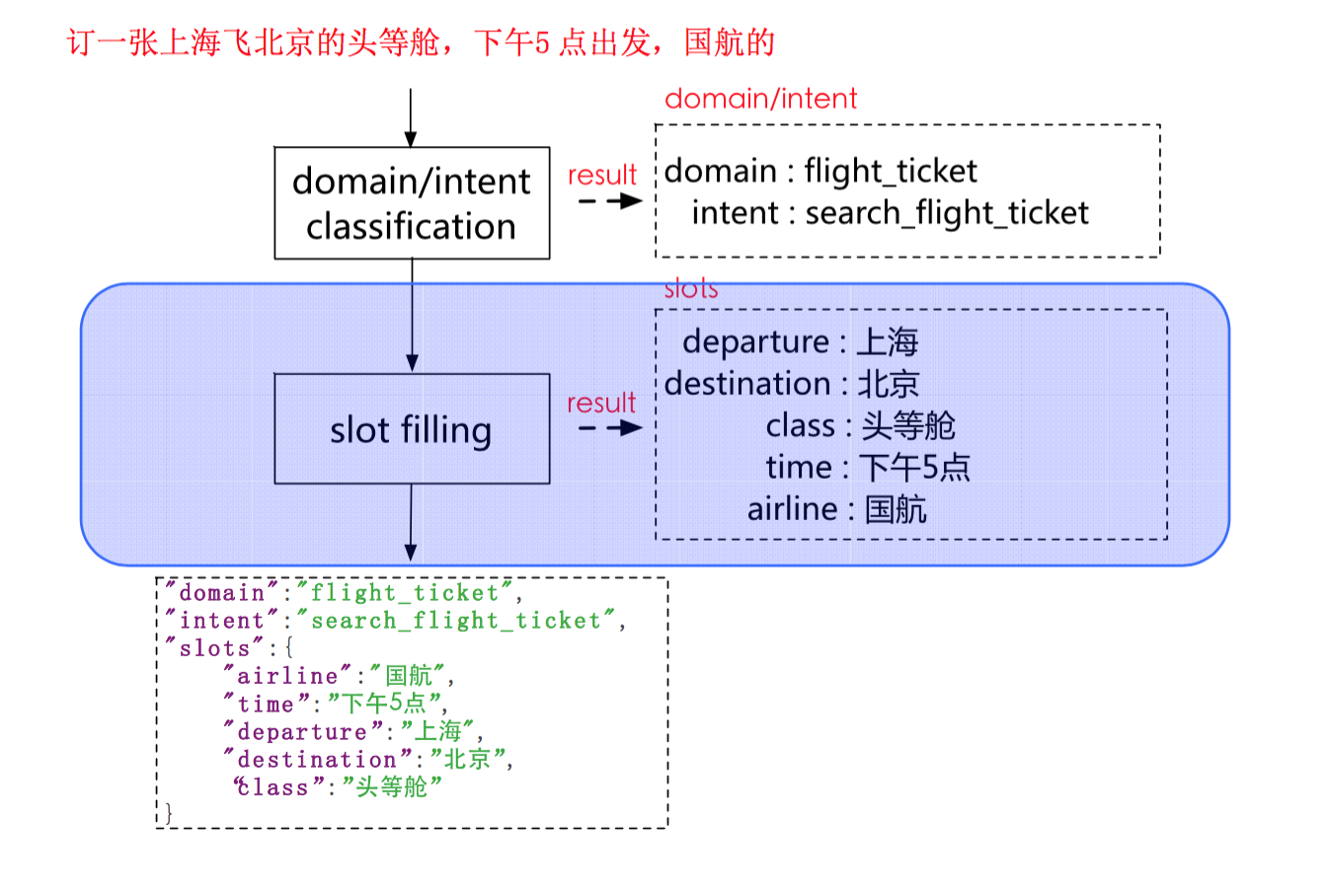
基本概念
来理解一下上面所说到的 domain 和 intent 的概念。
- domain
领域,同一类型的数据或者资源,以及围绕这些数据或资源提供的服务;
比如“地图”,“酒店”,“飞机票”、“火车票”等;
领域的目的其实是为了界定要解的 intent 范围,因为泛领域的 NLU 目前还做不到 - intent
意图,对于领域数据的操作,表示用户想要完成的任务,一般以动宾短语来命名;
比如飞机票领域中,有“查询机票”、“退机票”等意图;
然后就到了本篇重点,意图分类(intent classification),意图分类是一个典型的文本分类问题,所有传统的分类方法都可以使用,比如SVM/Decision Tree/Maximum Entropy 等等,数学形式来表示就是给定一个标注数据集合,$U={(u_1,c_1),…,(u_n,c_n)}$,其中,$c_i \in C$ 是具体的 intent,$u_i$ 是输入的 utterance,求解目标是
$$c_k = argmax_{c \in C}p(c|u_k)$$
主要难点
语言多样性
|
|
语言歧义性
|
|
解决语言歧义性的方法一般有下面 3 种
- 选一个 top intent,通常可能就选最常见的 intent
- 给一个 intent list 让用户来选
- 综合上下文信息来确定一个最优的 intent,这是最好的方法
语言鲁棒性
|
|
知识依赖
要知道语言是对现实世界的描述,很多词是有多种含义的,如果没有对现实世界的知识会难以分类。看下面的例子,大鸭梨可以是水果也可以是餐厅,七天可以是天数也可以是酒店。
上下文依赖(context)
上下文的概念包含了很多内容,比如说
- 对话上下文
多轮对话 - 设备上下文
指硬件设备,如手机/电视/汽车/… - 应用上下文
用户在哪个 app 里进行对话 - 用户画像
用户的个性化信息,尤其是地理位置等 - ……
如下面两段对话,上下文不同,宁夏的含义也就不同。
基本方法
- 基于规则(rule-based)
CFG
JSGF
…… - 传统机器学习方法
SVM
ME
…… - 深度学习方法
CNN
RNN/LSTM
…… - 融合规则和深度学习的方法
基于规则的意图分类
实际上是基于上下文无关语法(CFG),以上面提到的飞机票领域为例
从北京到上海的飞机票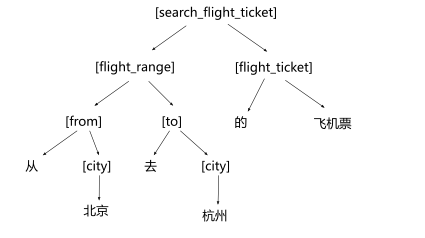
基于统计模型的意图分类
给定输入 utterance u 和类别 c,我们要求的是 P(c|u),核心问题就是:
- 如何表示 u,也就是 text representation
- 如何学习 P(c|u),也就是 classifer
Text Representation
- Bag of Words (BOW)
– 优点:简单
– 缺点:没有考虑语言结构,相似关系等 - Hand-crafted features
– 优点:精准
– 缺点:领域依赖,扩展性差 - Learned feature representation
– 优点:能够学到所有相关的信息
– 缺点:需要学习
Classifier
两类模型任君选择
- 生成式模型Generative (joint) models,计算 P(c,u)
– Naive Bayes
– HMM
– … - 判别式模型Discriminative (conditional) models, 计算 P(c|u)
– logistic regression
– maximum entropy
– conditional random fields
– support vector machines
– …
实现方案
一种简单的实现方案,首先用 bag of words 提取基本特征,接着人工定义规则来提取一些高质量的特征(提取意图词,过滤 stopwords 等),然后将这些特征用 one-hot 或者 tf-idf 方式表示为向量,再将特征向量喂给 svm 分类器。如下:
基于深度学习的意图分类
两种典型策略
- RNN(recurrent neutral network)
序列化、有记忆模型 - CNN(convolutional neutral network)
非序列化、无记忆模型
一般我们把 RNN/CNN 是特征学习方法,分类器可以有多种选择。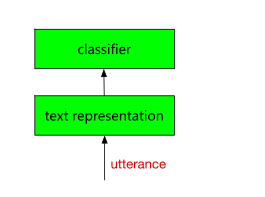
RNN(Recurrent Neutral Network)
从 language model 理解,
$$
\begin{aligned}
p(W_1=w_1, W_2=w_2,…,W_{L+1}=stop) & = p(w_1)p(w_2|w_1)p(w_3|w_1,w_2)…p(w_n|w_1,w_2,…w_{n-1}) \\
& = (\prod^L_{l=1}p(W_l=w_l|W_{1:l-1}=w_{1:l-1}))p(W_{L+1}=stop|W_{1:L}=w_{1:L}) \\
& = (\prod^L_{l=1}p(w_l|history_l))p(stop|history_L)
\end{aligned}
$$
其实也就是下图的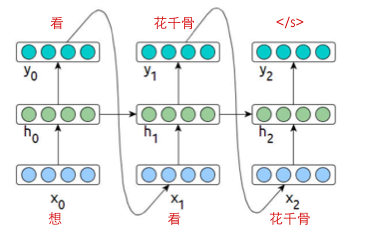
RNN 最后要加一层,一般是 softmax 分类。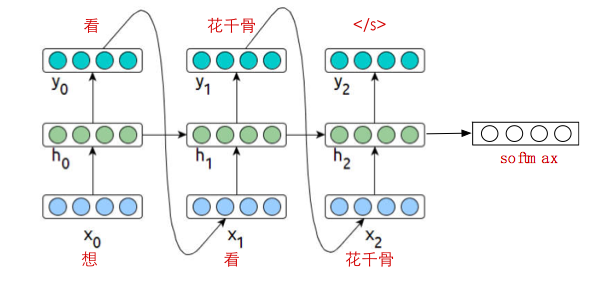
由于 RNN 的训练存在梯度消失/梯度爆炸问题,实际中往往采用 LSTM/GRU 等结构,Classifier 采用 softmax 函数,和网络一起训练
CNN(Convolutional neutral network)
之前讲过啦,见实习总结之 sentence embedding,一张图简单回顾。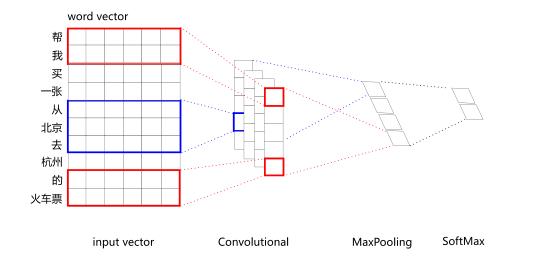
这里要说的是怎么将其用于意图分类。如果能够融入知识(如下图的语义标签),将 word vector 和 knowledge vector 结合起来,效果可能会有所提升。
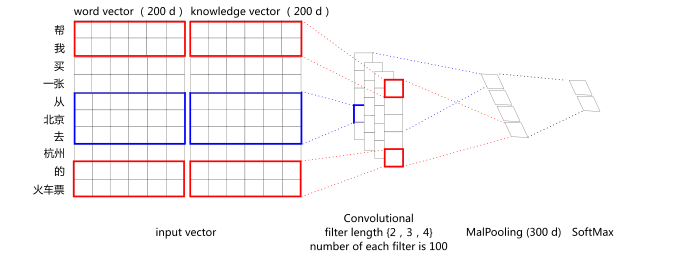
阿里巴巴做了实验,发现在他们自己 4k+ 的测试集上能带来 3% 的效果提升,并且,越是知识依赖严重的领域,效果越是明显,比如说在音乐、地图领域的提升比天气领域的提升明显很多。
融合规则和深度学习的系统
- 规则解决哪些问题?
冷启动
解bug
解业务特有意图 - 模型解决哪些问题?
海量数据下把问题解决的更加深入和彻底
解通用的意图
产品
意图分类在阿里产品中的使用,如汽车/阿里云/YunOS手机助理/支付宝/天猫魔盒/机器人等等。

